I used to follow the Linux kernel mailing list more closely, and one of the things you notice on that list is that people are not shy about being a jerk if they don't like your code. It's an interesting dynamic, because there's no obligation on the part of maintainers to accept your patch. No level of "I really need this code to go in to support or to make work properly" is likely to get your code in over the objections of the people in charge of that subsystem. 1
I don't think this approach is particularly good or bad. I do think it makes for an interesting counterpoint to commercial software development, when supporting or is literally going to make your company succeed or fail. In this world, quick and dirty hacks are often necessary. But if you plan on building your entire product out of such hacks, you're probably not going to get very far.
I like to think of the two approaches as optimizing for different things on the time axis. For example, let's use "cleanliness" to describe the code's adherence to design principles, coding standards, and consistency with other related code. And let's use "capability" to describe the software's ability to get something done with reasonably high chance of success.
In that case you might wind up with a set of plots that look like this:
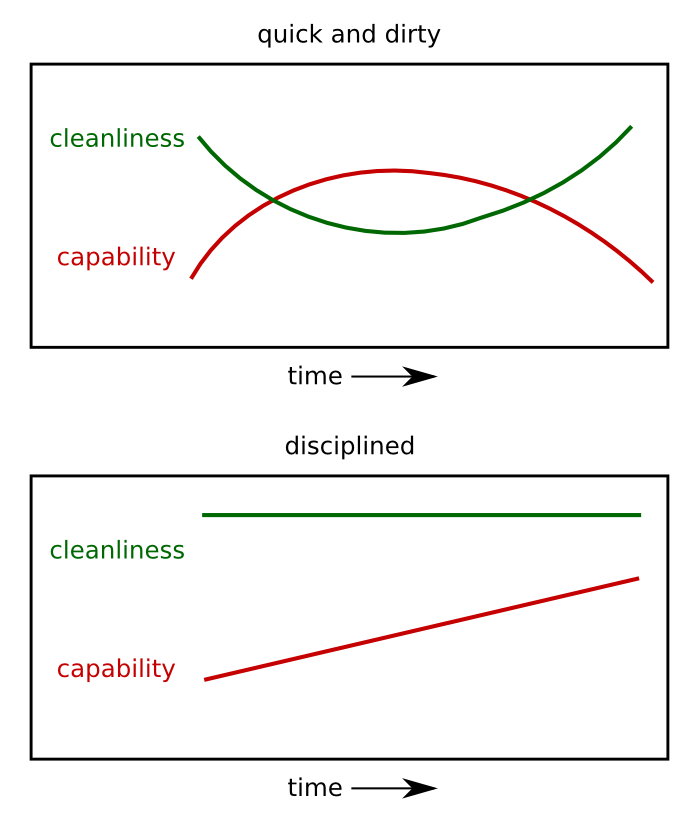
A really sloppy software shop might follow the "quick and dirty" model. They slap code together as quickly as possible, and see a rapid rise in capability. But over time their codebase becomes hard to understand and maintain, and eventually the bugs eat away at the functionality until the (perceived) capability starts to decay again.
On the other hand, a really disciplined group might ignore pressure for quick results and instead invest heavily in code maintenance, ensuring consistently nice code and a slow steady rise in capability.
The timescale of this graph might be five or ten years. If these two teams were startups, team quick-and-dirty probably got their product out the door first, got the first customers, and got additional funding to keep going. It's hard to see how the disciplined model could ever survive as a commercial enterprise. As customers ten years later, we'd probably prefer to be using software built using the disciplined model.
This is all all fiction, though, as every real software project exists somewhere in the middle, combining a measure of both approaches:
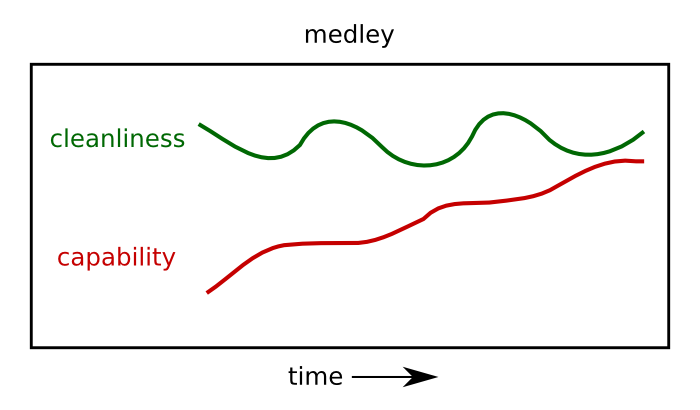
Code cleanliness might suffer briefly during periods of rapid development, but developers sneak in periods of code maintenance before things get too out of hand.
There's no easy way to measure "cleanliness" of code. It's mostly subjective, and different developers tolerate different levels of sloppiness. So there's bound to be a lot of debate over this; on a short timespan there really isn't an easy way to determine whether a particular chunk of code needs urgent cleanup.
For sure, there are plenty of red flags that help identify problem code:
- Code that is a frequent source of bugs because it's confusing or not unit-testable
- Code that is only understood by its original author, and conversations about modifications always end with "let's just assign this to X, because nobody else knows how to make this work."
- Commit messages or code review comments that say things like "this is not the best solution, but since there's no way for Foo to read the Bar status, this is the best I could do."
All of those are in hindsight, though. It's not hard to figure out where to apply your efforts if you have the benefit of a year's worth of bug reports on thousands of machines. Wouldn't it be great if we could identify those areas earlier, before they cause problems?
For my own code I try to extrapolate from the past. I have rough mental model based on the kind of code I wrote three years ago, and correction factors I apply to designs and code I'm working on today. For example:
- I should add about 50% more comments than instinct tells me are necessary.2
- I should probably break things into about twice as many pieces (functions; files; modules)
- When I imagine how many use cases there are for a piece of code, I'm should probably multiply that number by something between 2 and 5.
- My tolerance for "glue" code that lives outside the areas that are unit-testable should be about 1/10th of what my instinct tells me is reasonable.
- If I ever write a script while thinking "this will only be used in production for X months, and then we can retire it forever because of Y", there's a 90% chance that that's completely wrong, so I should just assume that everything I ever write will be used forever.
I still haven't gotten to the hard part, which is trying to apply these metrics and corrections to other people's code. But this has gotten kind of long, so I'll leave that problem for another day.
This is a gross oversimplification-- you can find crappy code in the kernel without looking very hard. If it helps, assume I'm talking about the core kernel code that's frequently seen and touched by some of the core developers.
I have a crappy memory, so I often need to consult the comments to understand how my own code from six months ago works.